Daha önceki yazımda Denetimsiz Makine Öğrenmesi‘ne kısaca değinmiş, belli başlı kullanılan algoritmalardan bahsetmiştim. Denetimsiz Öğrenme‘yi tekrar hatırlayacak olursak; Denetimsiz Öğrenme‘de veri setinde sadece input değerleri vardır ve dolayısıyla etiketlenmiş bir output değeri ve veya değerleri yoktur. Yani veri seti içindeki input değerleri içinde bağıntılar bularak anlamlı sonuçlar ortaya çıkarmaya çalışırız. İşte tam da bu aşamada Kümelenme algoritmaları işimize yarayacaktır.
Kümelenme algoritmaları, adından da anlaşılabileceği gibi, veri setindeki değerleri çeşitli parametreler yardımıyla anlamlı şekilde gruplandırmaya çalışır. Gruplar içindeki değerler, diğer gruplara göre kendi arasında benzerdir ve diğer gruplarla benzerlik olarak uzakdırlar. Kümelenme algoritmaları, Exploratory Data Analysis dediğimiz, veri elimize ilk geçtiğinde onu daha iyi anlamak için de kullanılır. Denetimli Öğrenmedeki algoritmalarına göre, veri setinin alındığı sahanın bilgisi ve algoritma sonuçları arasında subjektif verilen kararlar daha önemlidir. Kümelenme algoritmalarını kullanacağımız veri setinde etiketlenmiş veri olmadığı için, algoritmanın verimliliğini ölçerken, Denetimli Öğrenme algoritmalarında olduğu gibi, gerçek ve tahmin edilmiş veri arasındaki farkı ölçerek değil, grupların merkezleri arasındaki mesafeler ile ölçülür. (Similarity-Dissimilarity meselesi)
Gelelim Kümelenme algoritmalarının hangi alanlarda kullanıldığına. Kümelenme algoritmaları medyadan üretime, sağlık sektöründen hizmet sektörüne kadar çeşitli alanlarda kullanılabilir. Kümelenme algoritmalarının genel mantığının örnek üzerinden anlaşılması için müşteri segmentasyonu örneğini verecek olursak;
Şirketinizden yüzbinlerce müşterinin ürünlerinizi satın aldığını hayal edin. Ve bu müşterilerinizin ürünlerinizi daha da satın alması için kampanya yapmaya karar verdiniz. Elbetteki müşterilerinizin hepsi aynı satın alma karekteristiğine sahip olmayacaktır. İşte bu aşamada, müşterilerinizi Kümelenme algoritmalarıyla çeşitli gruplara ayırabilir ve bu grupların özelliklerine özgü kampanyalar düzenleyebilirsiniz.
Peki elimize bir veri seti geçtiğinde hangi Kümenlenme algoritmalarını kullanabiliriz? Python ile kullanacabileceğiniz en önemli makine öğrenmesi kütüphanelerinden biri olan scikit-learn kütüphanesinde 10 adet Kümelenme algoritması bulunur. Bunlar sırasıyla;
- Affinity Propagation
- Agglomerative Clustering (Hiyerarşik)
- BIRCH
- DBSCAN
- K-Means
- Mini-Batch K-Means
- Mean Shift
- OPTICS
- Spectral Clustering
- Mixture of Gaussians
Yukarıda sayılan algoritmaları kendi aralarında matematiksel modellemelerine bakarak karşılaştıracak olursak, şu dört maddeyi sayabiliriz;
Model Parametreleri: Özellikle scikit-learn kütüphanesinde modeli oluştururken kullanılan parametrelerin ne için kullanıldıklarını ve hangi değerler için tuning yapılması gerektiğini iyi bilmeliyiz. Bunun için her zaman kütüphanenin dokümentasyonunu iyi okumanızı ve anlamınızı tavsiye ederim.
Ölçeklenebilirlik: Elimizdeki veri setinin ne kadar büyük olduğu ile alakalı bir durum. Örneğin; BIRCH algoritması büyük veri setleri için iyi çalışırken, K-Means algoritması büyül veri setleri için uygun olmayabilir.
Use-Case: Elimizdeki veri setinin hangi alandan geldiğine ve ne sonuç elde etmek istediğimize göre belirli algoritmaları kullanmak daha iyi olacaktır.
Geometri: Gruplandırma işlemini yapmak için veri setindeki veri noktaları arasındaki mesafeyi ölçmeyi yapmak için algoritmalarda kullanılan hesaplama yöntemleri de farklı sonuçlar doğurabilir.
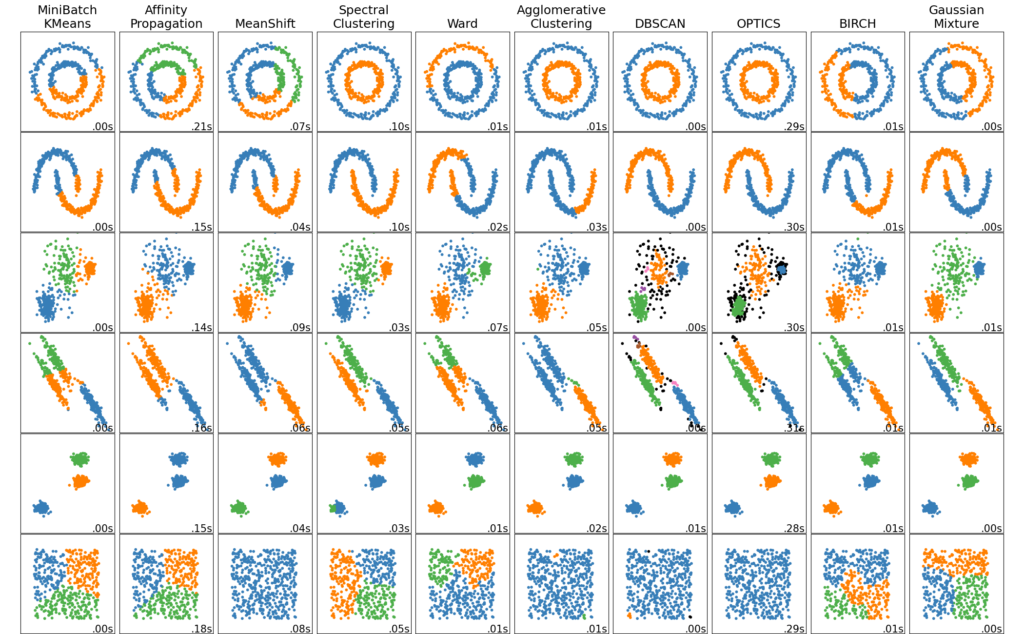
Yukarıdaki scikit-learn kendi sitesinden aldığım grafiklerde, farklı Kümelenme algoritmalarının aynı veri seti üzerinde aynı parametreleri kullanarak nasıl sonuçlar verdiğini görebilirsiniz. Grafiklerde her renk farklı bir kümeyi temsil ederken, kümelenmelerin nasıl gerçekleştiğini ve küme sayısını farkedebilirsiniz. Burada hangi algoritmanın daha iyi sonuç verdiğini söylemek maalesef zor. Biraz önce saydığım 4 maddeyi düşünerek uygun algoritmayı seçmeliyiz.
Kümenlenme algoritmalarının çalışma mantığını örnekler üzerinden daha iyi anlamak için ilerleyen yazılarımda buluşmak üzere!
Sağlıcakla kalın!
Kaynak:
https://scikit-learn.org/stable/auto_examples/cluster/plot_cluster_comparison.html