Daha önceki yazımda denetimli makine öğrenmesinin tanımını yapmış, genel çalışma mantığını anlatmış ve örneklerle pekiştirmiştim. Denetimsiz Öğrenme, denetimli öğrenmenin tersi olarak, etiketlenmemiş veriyi çeşitli algoritmalar kullanarak analiz eder ve veri içindeki gizli kalmış bağlantıları ve gruplanmaları ortaya çıkartır. Denetimsiz Öğrenmede ham veriye bizim müdahale etmemize gerek yoktur.
Denetimsiz Öğrenme algoritmalarını kullanacağımızda, veri setindeki girdi değerlerinin herhangi bir etiket ile etiketlenmesine ve dolayısıyla veri setinde çıktı değerleri olmasına gerek kalmaz. Denetimsiz Öğrenme çıktı değerini kendisi oluşturur ve veriyi gruplara böler veya bağlantıları bulur. Denetimsiz Öğrenmeye örnek verecek olursak; elimizde çeşitli hayvan resimlerinin olduğunu ve bu resimlerin hayvanların türlerine göre isimlendirilmediğini düşünün. Veri setimizi Denetimsiz Öğrenme algoritmasına koyduğumuzda, algoritma verilerin içindeki benzerlikleri bularak hayvan resimlerini kümelendirir ve hayvanları türlerine ayırmamıza yardımcı olur. Sayıca az veri veya gruplandırma içeren veri setlerinde bu tarz gruplandırmaları veriye baktığımızda belki ilk bakışta anlayabiliriz. Ama karmaşık veri setlerinde Denetimsiz Öğrenme algoritmaları çok işimize yarayacaktır.
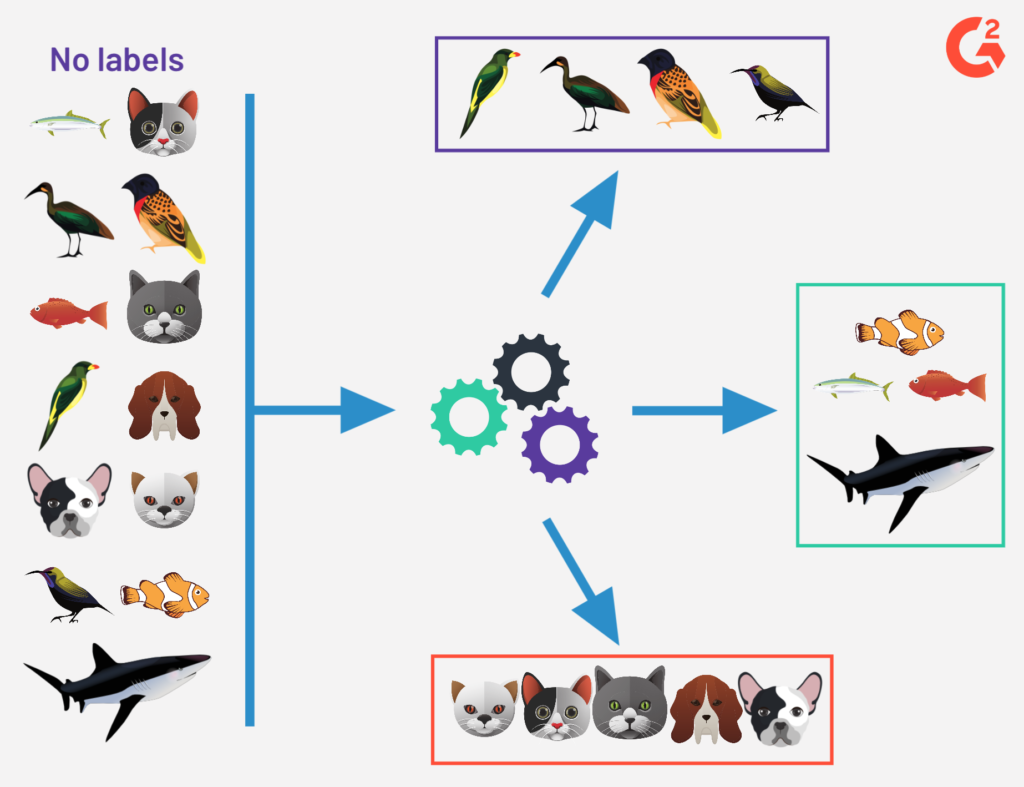
Gelelim Denetimsiz Öğrenmenin uygulanma metotlarına göre çeşitlerine. Denetimsiz Öğrenme tiplerini genel olarak 2 ana başlık altında toplayabiliriz. Bunlar sırasıyla; Clustering (Kümelenme) ve Association Rules (Birliktelik Kuralları)
Clustering – Kümelenme
Kümelenme tekniği veri setimiz içindeki benzerlikleri veya farklılıkları yakalayarak verimizi gruplandırmamızı sağlar. Kümenlenme algoritmaları elimizdeki ham ve sınıflandırılmamış veriyi çeşitli işlemlerden geçirerek veri içerisinde bulunan yapıları veya işaretleri/etiketleri ortaya çıkarır. Kümenlenme algoritmalarının günlük hayatta nasıl kullanıldığına bakacak olursak; örneğin bir firma müşterilerini harcama alışkanlıklarına göre gruplandırarak onları karakterize edebilir ve pazarlama stratejisini müşteri gruplarına göre geliştirebilir. Veya biyolojide farklı bitki veya hayvan türlerini gruplandırmada kullanılabilir.
Peki Kümelenme tekniğini kullanmak için hangi metotları kullanabiliriz? Sıralayacak olursak;
- Hierarchical Clustering
- Centroid-Based Clustering
- Denstiy-Based Clustering
- Distribution-Based Clustering
Kümelenme metotlarını isim olarak gördük. Hepsini ilerleyen yazılarımda açıklayacağım. Peki bu metotları ile kullanmak için hangi Kümelenme algoritmalarını kullanabiliriz? Önemlilerini yazacak olursak;
- K-Means Algoritması
- DBSCAN (Density-based spatial clustering of applications with noise)
- Gaussian Mixture Model algorithm
- BIRCH (Balance Iterative Reducing and Clustering using Hierarchies)
- Affinity Propagation clustering algorithm
- Mean-Shift clustering algorithm
- OPTICS algorithm
- Agglomerative Hierarchy clustering algorithm
Association Rules (Birliktelik Kuralları)
Adından da anlaşılabileceği gibi, Birliktelik Kuralları elimizdeki veri setinin içindeki ilişkileri yakalar. E-ticaret sitelerinde ürün sayfasına girdiğinizde “Bu ürünü alanlar şu ürünü de aldı” gibisinden bir alan görmüşsünüzdür. İşte Birliktelik Kuralları algoritmaları tüm müşterilerin geçmiş siparişlerini inceler, onların bir alışverişte hangi ürünleri beraber aldıklarını analiz eder ve siz istediğiniz bir ürünü almak istediğinizde, tabiri caizse biraz da aklınızı çalarak, size o ürünün yanında alınan ürünleri satın almanızı tavsiye eder. Böylelikle şirket daha fazla ürün satarak karlılığını korumak amacı güder.
Birliktelik Kuralları için algoritmları şöyle sıralayabiliriz;
- Apriori (En yaygın kullanılan)
- Eclat
- FP-Growth
Bu iki Denetimsiz Öğrenme çeşidinin dışında kaynalarda bir de Dimensionality Reduction tekniğini görebilirsiniz. Bu tekniği de ilerleyen yazılarımda açıklamayı düşünüyorum.
Gelelim Denetimsiz Öğrenmenin avantaj ve dezavantajlarına;
Avantajları
- Denetimli Öğrenme metotlarına kıyasla kompleks verilerle çalışılması daha kolaydır.
- Verinin etiketlenmesine gerek yoktur.
- Ham verinin anlaşılmasına yardımcı olur. EDA (Exploratory Data Analysis) için hazırlık oluşturur.
Dezavantajları
- Çıkan sonuçların hatalarının daha yüksek olma riski
- Modele eğitim yaptırırken uzun zaman alması
Bir sonraki yazılarımda buluşmak üzere!
Öğrenmeye her zaman devam!
Kaynak:
1 – https://www.g2.com/articles/supervised-vs-unsupervised-learning