Denetimli Öğrenme (Supervised Learning), adından da anlaşılabileceği gibi, etiketlenmiş veriyi çeşitli algoritmalar ve sıralı sistemler vasıtasıyla analiz ederek veri setinden anlamlı tahminler çıkarmayı ifade eder. Tanım cümlesinde de geçtiği gibi, makine öğrenmesinin diğer çeşidi olan denetimsiz öğrenmeden farkı, verinin etiketlenmiş, yani çıktı verisinin çeşitli girdi verileriyle (kategorik veya nümerik veri) ilişkilendirilmiş olmasıdır. Computer Vision alanından örnek verecek olursak; örneğin, elimizde kedi resimlerinden oluşan bir veri setinin olduğunu düşünün. Bu resimlerin üzerinde, kedilerin olduğu yerleri işaretleyerek veri setini etiketlenmiş hale getiririz ve dolayısıyla makine öğrenmesi algoritmasında da verinin eğitimini, yani öğrenmeyi amaçlamış oluruz.
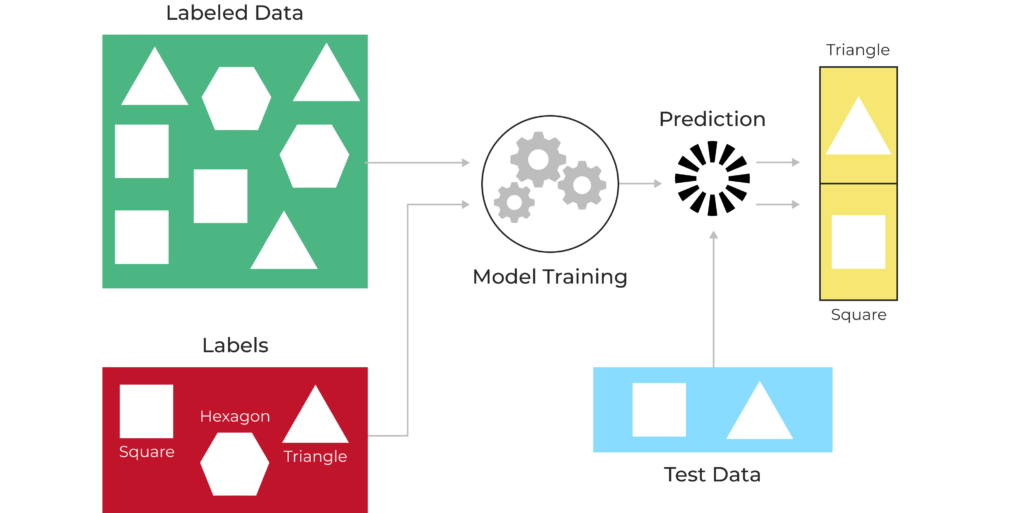
Denetimli Öğrenme, modelimizi eğitmek için ayırdığımız veri setinden faydalanarak doğru tahminler yapmayı amaçlar. Bu tahminleri elde ederken veri setimiz, çeşitli girdi değerleri ve doğru çıktı değerlerinden oluşur. Algoritmalar doğru çıktı ve tahmin edilen değer arasındaki hata farkını azaltarak, tahmin değerlerimizdeki verimliliği arttırır.
Daha önceki yazılarımda, elimizde olan verinin çeşidini bilmenin bize makine öğrenmesi metotlarını kullanmada işimize yaracağını söylemiştim. Veri çeşidini bilmek, doğru modeli/algoritmayı kullanmamızı ve doğal olarak iyi sonuçlar almamızı sağlayacak. Veri setlerinden, veri çeşitlerini anlatığım yazımdan da yararlanacak olursak, sayısal (nicel) bir değer tahmin edebiliriz ya da kategorik (nitel) bir tahmin değeri modelimizden alabiliriz. Peki Denetimli Öğrenmeyi kendi veri setimiz için kullanmak istiyorsak, genel olarak hangi tarz modellerle çıktımızı tahmin edebiliriz? İşte Denetimli Öğrenme bu noktada ikiye ayrılıyor.
Sınıflandırma Modelleri
Veri setinden kategorik tahmin elde etmemizi sağlayan modellerdir. Eğer sonuç olarak iki değerden birini tahmin etmek istiyorsak, binary classification, daha fazla tahmin almak istiyorsak, multi-class classification modellerini kullanmamız gerekir. Örnek olarak, biraz klasik olacak ama, bize gelen mailleri spam veya spam değil diye ayıran denetimli öğrenme modeli binary classification olarak adlandırılır. Sınıflandırma modellerinin verimliliği accuracy metriği ile ölçülür ve bu değer modelin yaptığı doğru tahminlerin, modelin toplam yaptığı tahmin sayısına oranıdır. Sınıflandırma algoritmalarına örnek verecek olursak;
- Karar Ağacı (Decision Tree)
- Random Forest
- Support Vector Machine
- Naive Bayes
- Logistik Regresyon
- K-Nearest Neighbour
Regresyon Modelleri
Veri setindeki sayısal değerleri kullanarak, sayısal tahminler elde etmemizi sağlayan modellerdir. Bu modellerde, bağımsız (independent) değişkenlerle, bağımlı (dependent) değişkenler tahmin edilir. Regresyon modellerinde, sürekli (continuous) veri tahmin edilir ve girdi değerleri continuous veya discrete olabilir. Girdi ve çıktı değerleri arasında korelasyon bulunarak aralarındaki ilişkilere bakılır. Eğer feature olarak tek bir girdi sütunumuz varsa basit (simple), birden fazla girdi sütunumuz varsa çoklu (multivariate) regresyon modelleri kullanılır. Girdi değerleri kendi arasında yüksek korelasyon değerlerine sahip olmamalıdır.
Regresyon modelleri hava durumu, satış tahmini gibi sayısal çıktı veren durumlarda kullanılır. Zamana dayalı değişen output değerlerini tahmin etmede de çok kullanılır. Regresyon kullanımına örnek verecek olursak, yine klasik olacak ama, oda sayısı, metrekare vs. gibi değerlerle bir evin satış fiyatını tahmin eden bir modeli regresyon ile oluşturabiliriz. Regresyon modelimizin verimliliğini ölçmede genelde kullanılan metrik RMSE (Root Mean Squared Error) metriğidir ve bu metrik tahmin çizgisiyle gerçek değerler arası farkların karesinin ortalamasının kareköküyle bulunur. (RMSE tanımını uzun bir cümleyle yaptım ama formülü ve grafikleri ilerleyen yazılarımda gördüğünüzde daha iyi anlayacaksınız.) Regresyon algoritmalarına örnek verecek olursak;
- Lineer Regresyon
- Ridge Regresyon
- Neural Network Regresyon
- Lasso Regresyon
- Decision Tree Regresyon
- Random Forest Regresyon
- KNN Modeli
- Support Vector Machine Regresyonu
- Gausian Regresyon
- Polinom Regresyon
Yukarıda saydığım sınıflandırma ve regresyon algoritmalarının her birini, hiç olmazsa en çok kullanılanlarını ilerleyen yazılarımda ayrı ayrı açıklamayı düşünüyorum. Algoritmaların çalışma mantığını ve içindeki parametreleri bilmek, elimize bir veri seti geçtiğinde doğru algoritmayı seçmemizi ve dolayısıyla sağlıklı tahminler yapmamızı sağlayacak. Örneğin, forecasting diye tabir edilen gelecekteki değerleri tahmin eden modellerde lineer ya da support vector machine regresyon uygun iken bu tarz problemlerde decision tree ya da random forest regresyonu kullanmak iyi değildir. Çünkü her ikisi de kendine verilen değer aralığı içinde doğru tahminler yapabilir ve gelecek tahmini yapmak için elverişli değildir.
Gelelim denetimli öğrenmenin avantaj ve dezavantajlarına;
Avantajları
- Modelinizde kullanacağınız verinin eğitim kısmında sonuçların sınıfları/etiketleri hakkında kesin bilgi sahibi olursunuz.
- Genel olarak uygulaması kolaydır. Modelin içindeki mantıksal bağıntıları kolay anlayabilirsiniz.
- Sınıflandırma problemlerinde çok işe yarar.
Dezavantajları
- Bazı kompleks işlemlerin uygulanmasında iyi değildir.
- Denetimsiz öğrenmenin tersine, veri seti içinden çıkarım yapılmasını, daha doğrusu bilmediğimiz bir bilginin çıkmasına imkan vermez.
- Modeli oluşturmadan önce ön işleme (preprocessing) işlemleri bazen çok miktarda gerekir.
Bir dahaki yazımda görüşmek üzere!
Sağlıcakla kalın!
Kaynak:
1-https://postindustria.com/how-to-know-which-machine-learning-algorithms-to-use-techniques-in-machine-learning/